|
I am a postdoctoral research fellow working with Asst.Prof. Josie Hughes at Swiss Federal Technology Institute of Lausanne (EPFL), Switzerland. Previously, I worked with A.P. Qi Wu, at Australian Institute for Machine Learning (AIML), The University of Adelaide, where I completed my Ph.D. in Computer Science under the supervision of A.P. Qi Wu and Dr. Yuankai Qi. My research interests lie broadly in the field of Vision and Language, Embodied AI, and AI-Driven Robotics Design.
|

|
News[Sept. 2025] Two papers are accepted by NeurIPS 2025.[Aug. 2025] Two papers are accepted by EMNLP 2025. [Jun. 2025] One paper is accepted by ICCV 2025 and two papers are accepted by IROS 2025. [Apr. 2025] MiniVLN has been selected as ICRA 2025 Best Paper Award Finalist. [Jan. 2025] One paper is accepted by ICLR 2025 and four papers are accepted by ICRA 2025. |
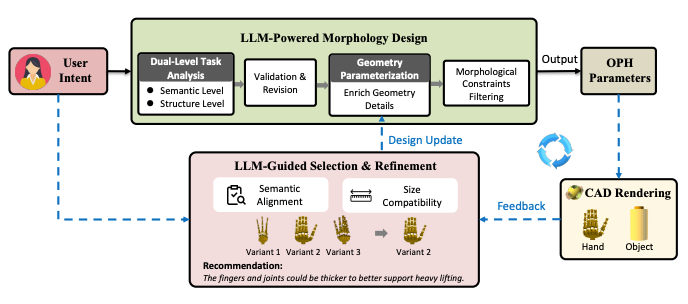
|
Yanyuan Qiao, Kieran Gilday, Yutong Xie, Josie Hughes arxiv |
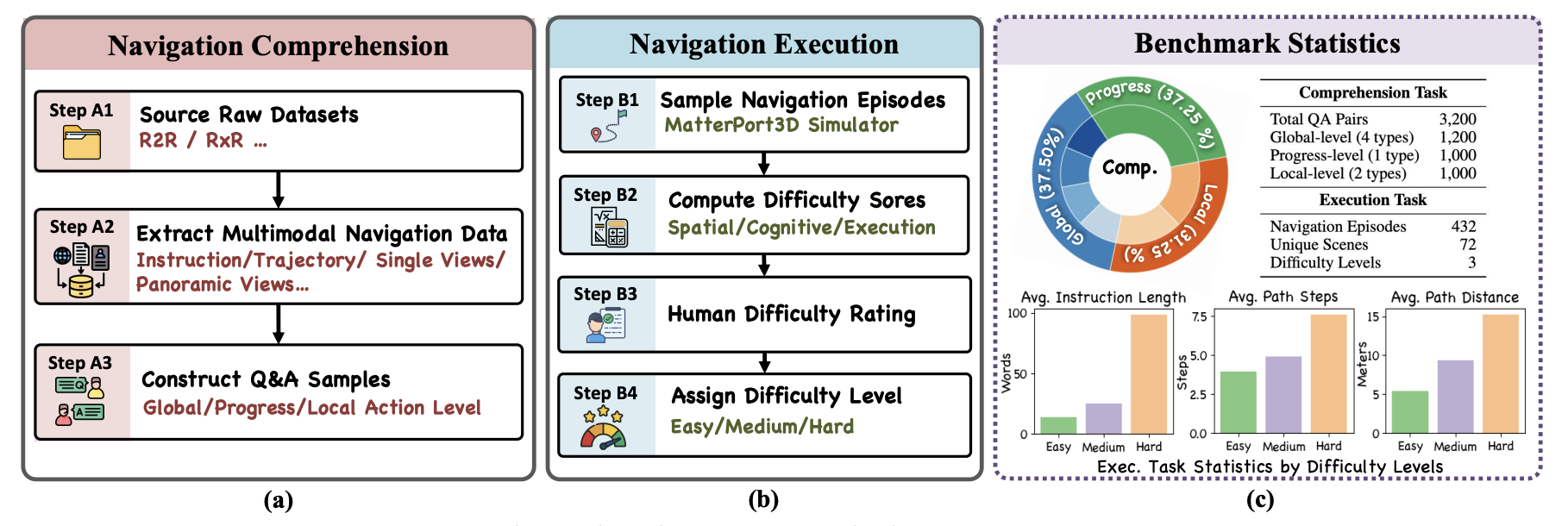
|
Yanyuan Qiao, Haodong Hong, Wenqi Lyu, Dong An, Siqi Zhang, Yutong Xie, Xinyu Wang, Qi Wu Conference on Neural Information Processing Systems (NeurIPS), 2025 project / arxiv |
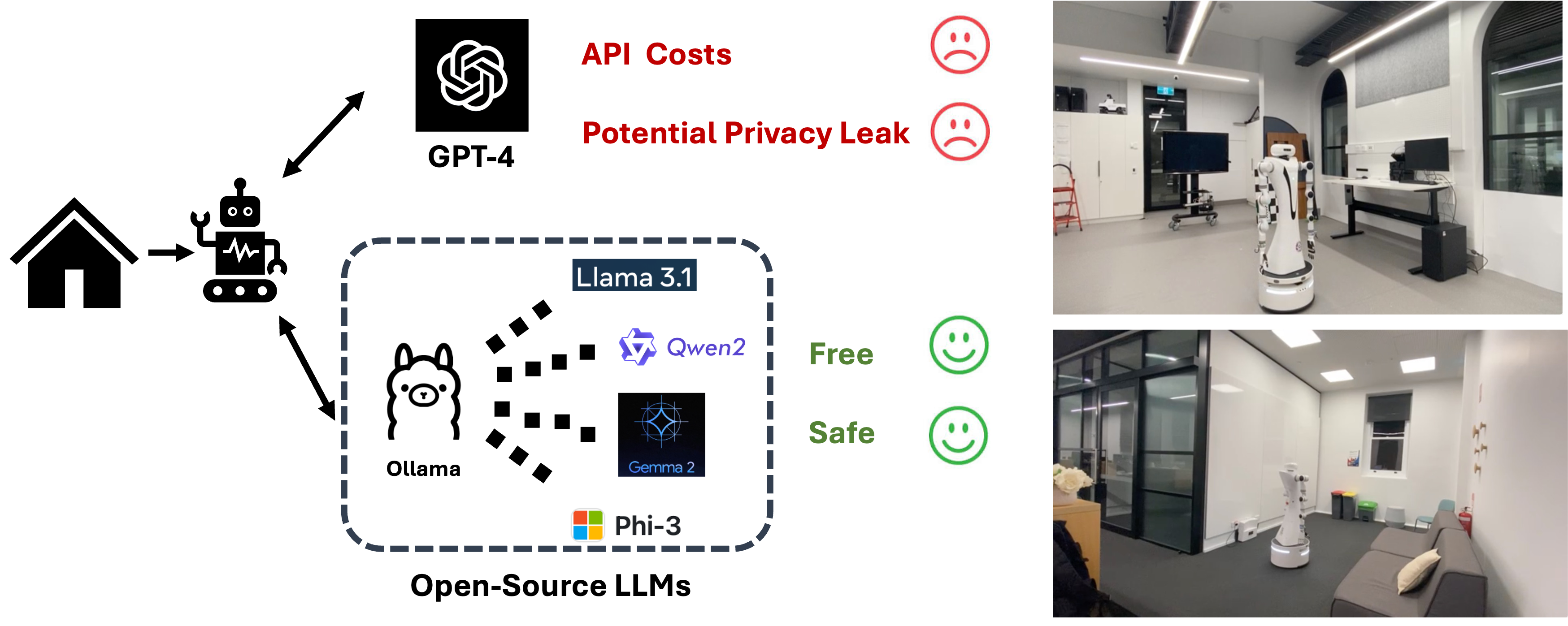
|
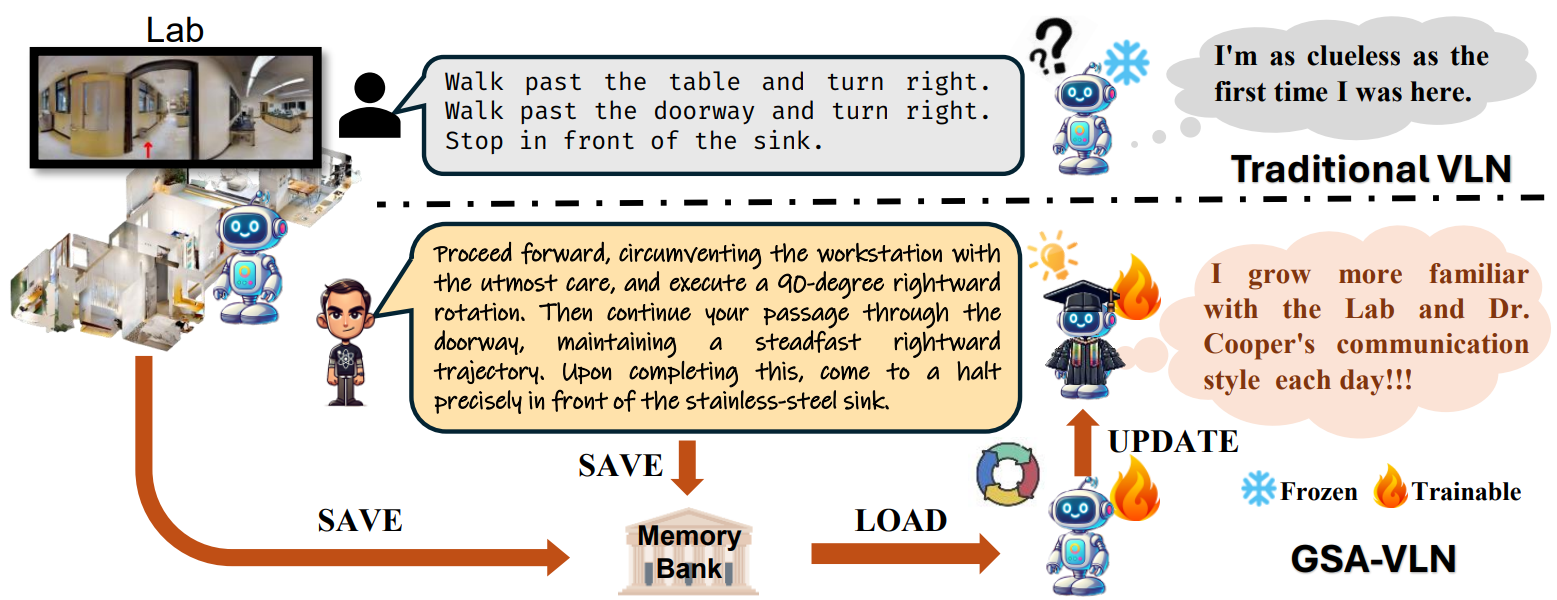
Yanyuan Qiao, Wenqi Lyu, Hui Wang, Zixu Wang, Zerui Li, Yuan Zhang, Mingkui Tan, Qi Wu International Conference on Robotics and Automation (ICRA), 2025 project / arxiv |
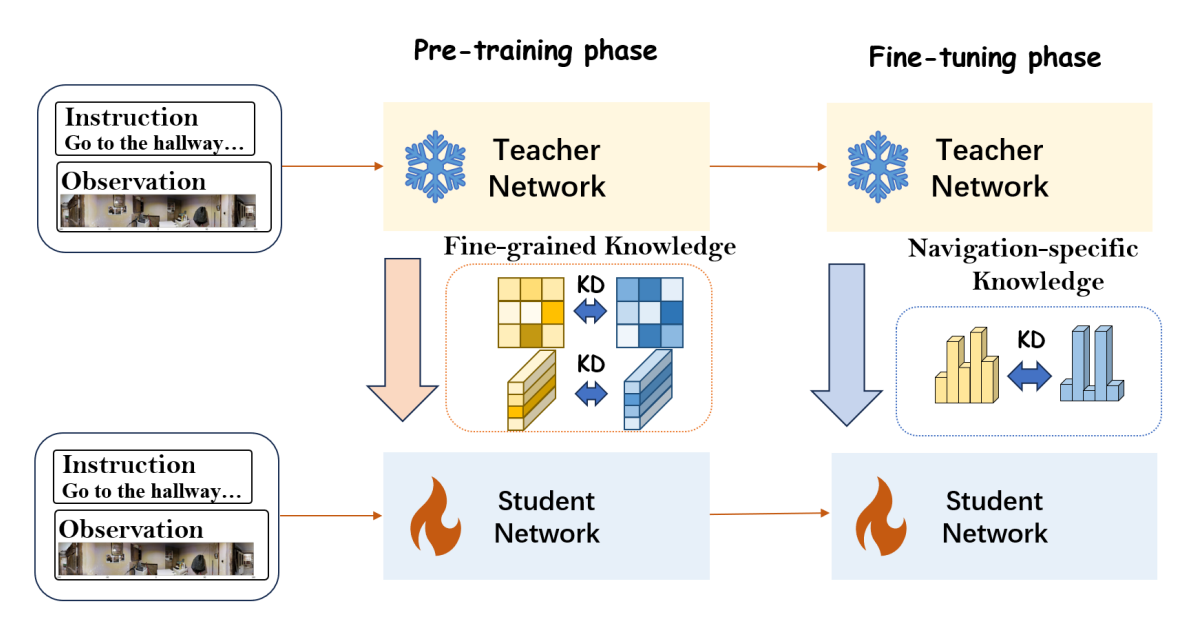
|
Junyou Zhu, Yanyuan Qiao, Siqi Zhang, Xingjian He, Qi Wu, Jing Liu International Conference on Robotics and Automation (ICRA), 2025, Best Paper Finalist arxiv |
|
Haodong Hong, Yanyuan Qiao, Sen Wang, Jiajun Liu, Qi Wu International Conference on Learning Representations (ICLR), 2025 paper |
|
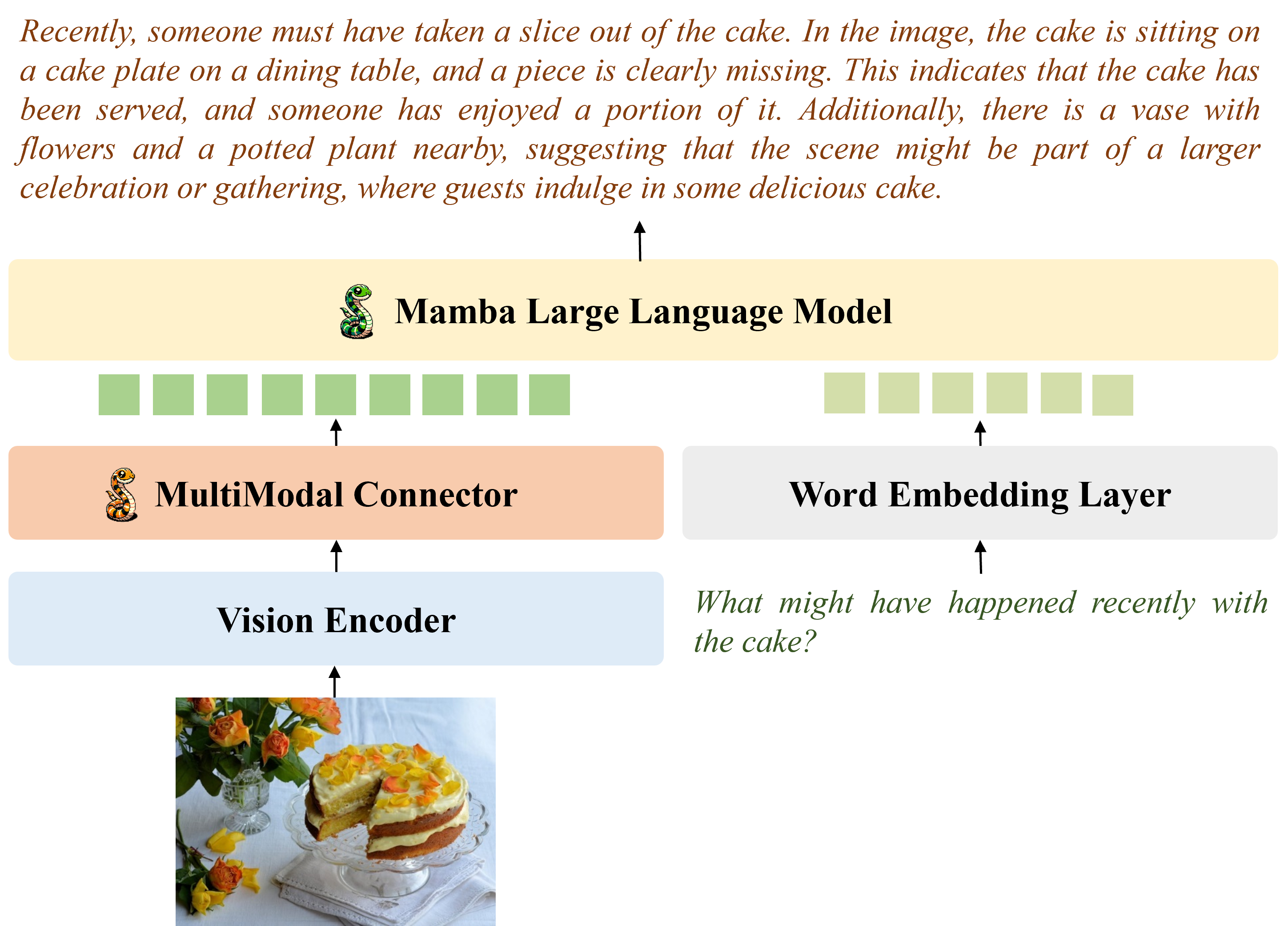
Yanyuan Qiao, Zheng Yu, Zijia Zhao, Sihan Chen, Mingzhen Sun, Longteng Guo, Qi Wu, Jing Liu NeurIPS Workshop on Efficient Natural Language and Speech Processing, 2024 project / arxiv / code |
|
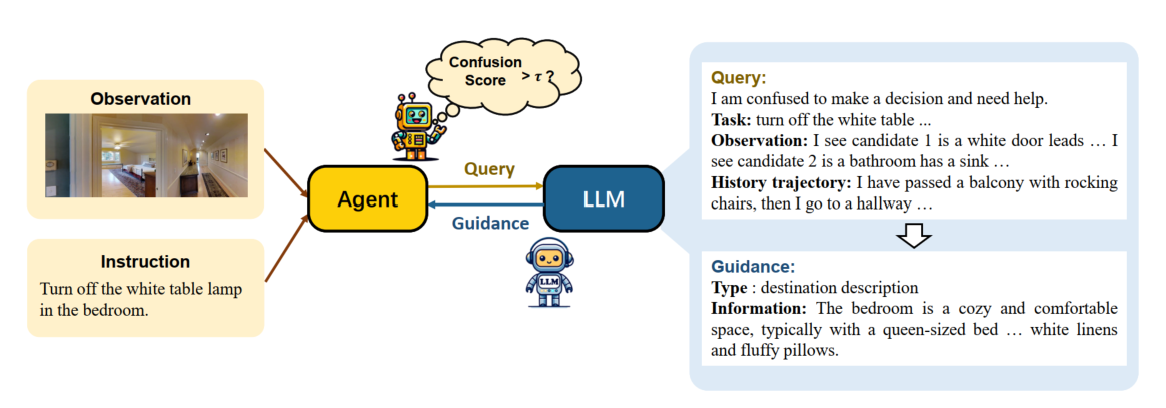
Yanyuan Qiao, Qianyi Liu, Jiajun Liu, Jing Liu, Qi Wu European Conference on Computer Vision (ECCV), 2024 paper |
|
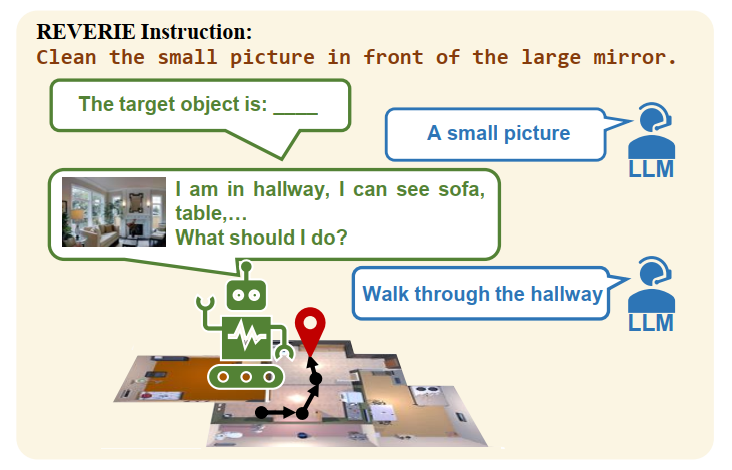
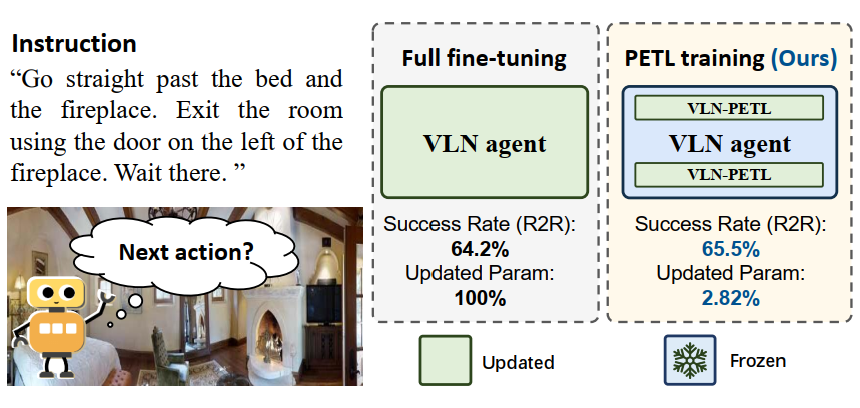
Yanyuan Qiao, Yuankai Qi, Zheng Yu, Jing Liu, Qi Wu International Conference on Computer Vision (ICCV), 2023 paper / arxiv / code |
|
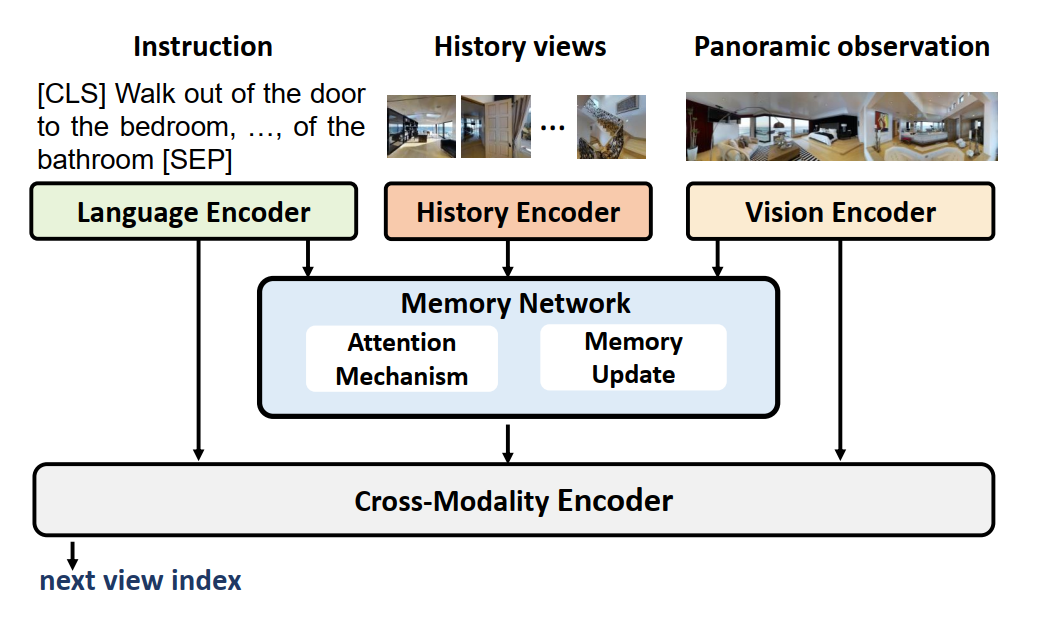
Yanyuan Qiao, Zheng Yu, Qi Wu International Conference on Computer Vision (ICCV), 2023 paper / arxiv / code |
|
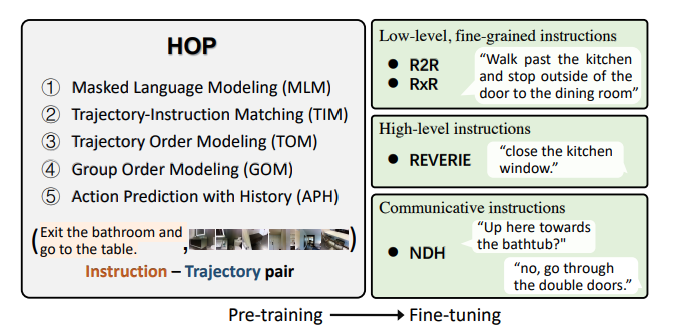
Yanyuan Qiao, Yuankai Qi, Yicong Hong, Zheng Yu, Peng Wang, Qi Wu IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023 paper |
|
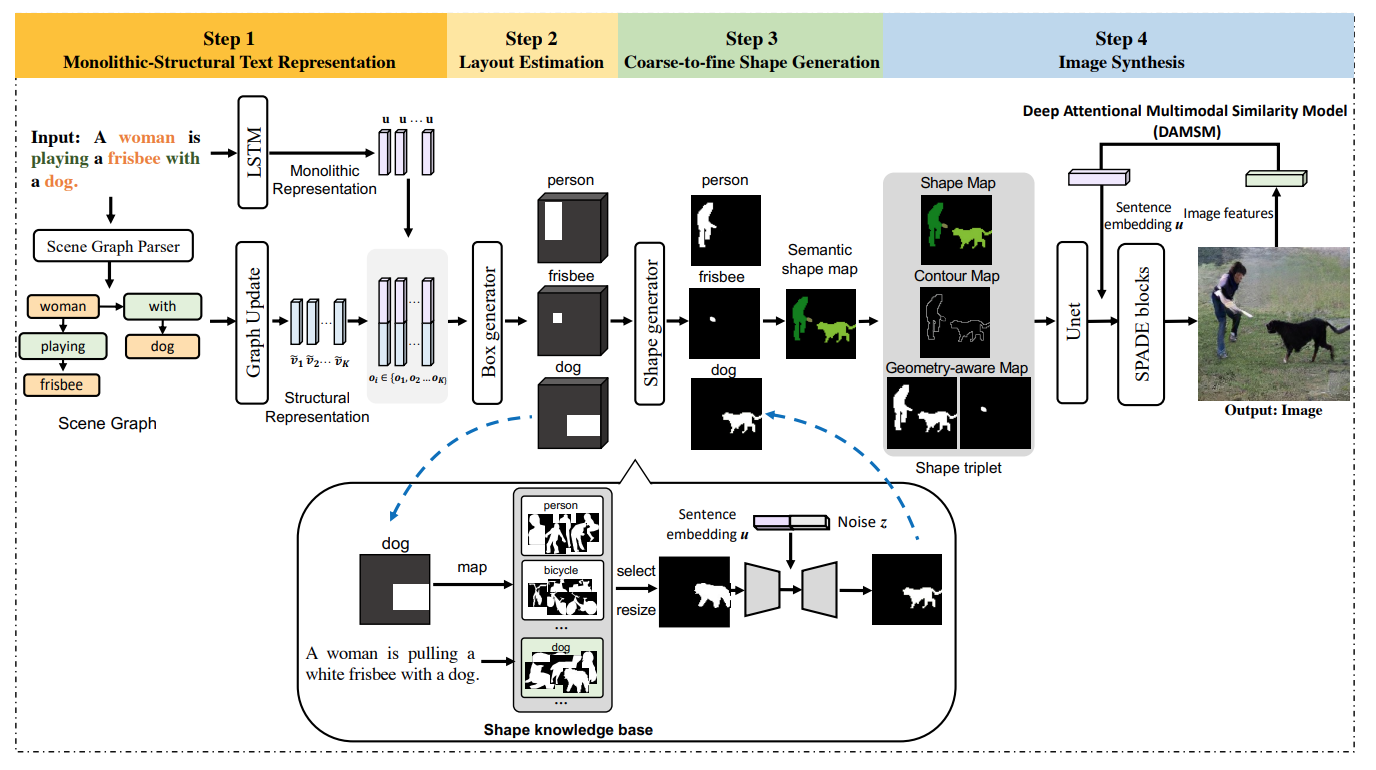
Yanyuan Qiao, Yuankai Qi, Yicong Hong, Zheng Yu, Peng Wang, Qi Wu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022 paper / arxiv / code |
|
Yanyuan Qiao, Qi Chen, Chaorui Deng, Ning Ding, Yuankai Qi, Mingkui Tan, Xincheng Ren, Qi Wu. ACM International Conference on Multimedia (ACM MM), 2021 paper |
|
|
